



by Rob Aaldijk, on Mar 11, 2024 3:17:36 PM

Making the right choices to avoid headaches
If you are planning to manage information compliance on your Microsoft 365 platform, or have started to implement it, it is worthwhile to consider how your information is currently organized. For you as an IT manager, compliance manager, or records manager, the reason to do this is compelling enough: the only realistic way to apply compliance to your vast body of corporate information is to rely on automation. Leaving it to manual governance procedures is simply too time-consuming and risky.
The way to manage compliance in Microsoft 365 is by deploying Microsoft Purview, which includes a vast toolkit to apply automated data lifecycle management and records management.
This immediately shifts the pressure to the information model you adopted in Microsoft 365, notably SharePoint, where most of your documentary information will be stored. While SharePoint has a large toolbox for structuring your information, ensuring that this structure meets the needs of automated compliance and data retention with Purview is an entirely different matter.
Still, there are options to choose from. In this article, I want to highlight several of them based on a practical example.
Let’s consider the following retention schedule:
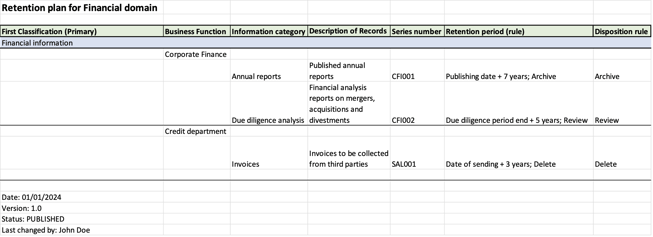
Figure 1- Example retention schedule for the Financial domain of a company
As you can see in the figure, within this example retention schedule we have three categories of information, each with a different retention rule: Annual reports, due diligence analysis reports, and invoices. The first two belong to the Corporate Finance business function, the second one to the Credit department. Each category is identified by a unique series number.
Now if we want to automatically relate the retention period to relevant information stored in Microsoft 365, in this example we can achieve that in the following ways:
- Relate the information to the information category it belongs to.
- Relate the information to the unique series number of that category.
- Directly relate the information to the retention period, which in Microsoft 365 Purview is either expressed as a retention policy or a retention label. This can be done manually or automatically.
In this case, it would NOT work to associate the information with a relevant business function or with the primary information classification of ‘Financial Information', as they are on an aggregate level and would not allow for separated retention periods to be allocated.
Let’s dive into the details of each option:
Ad 1. In SharePoint, we can model information categories in several ways, and each would work to support automated retention:
- We can define SharePoint content types to reflect information categories and classify our information accordingly when creating or uploading it to a SharePoint site library. This approach is only practical if we do not have hundreds of information categories defined, as the use of custom content types mostly makes sense when there is a lot of diversity in the attributes of a certain category of information.
In case there ARE many types of information, as is typically the case at an enterprise level, there are other ways to model this in SharePoint:
- By defining a managed metadata column or a choice list reflecting the information categories. With the first option, you can also define multiple levels (categories and subcategories). The consequence of this approach is that all items in SharePoint must be allocated the exact category they belong to, which might be a challenge if you rely on end users to apply them.
There are ways to tag information after creation or upload (e.g. using SharePoint Premium auto-extraction and matching features), but with many categories, this may not work properly or will become very time-consuming to configure properly.
A better alternative is to tag the information as part of the business process of creation or upload, e.g. with a PowerAutomate workflow or by integration with a primary business system that controls the process. - By using enterprise keywords. This is a less strict way of tagging information compared to using managed metadata, which also is its weakness, as tagging mistakes are made more easily.
- By using a choice list attribute. This is not advised in the case of many categories, but if you combine it with the use of content types, this might become manageable. As this option suggests, strategies a. and b. may be combined: a content type reflecting the main category of information, and a unique attribute defined within the content type to reflect sub-categories. This is the construct I would recommend in most cases.
Ad 2. and Ad 3. Relating categories of information to their corresponding series number or applying record labels manually is only recommended for record managers. If you leave this to end users, they will typically not be able to relate to or judge which ID or label belongs to which category, unless they are fully familiar with ‘their’ part of the retention schedule. Still, this approach may work in an enterprise environment where there is a sizeable community of record managers, who work in a specific business function. What will work better is the automated application of policies and/or labels, however, this relies in all cases on how the information is structured, which brings us back to the approaches laid out in Ad 1.
Once an information model has been implemented, the automation in Purview is achieved by defining retention policies or labels and appropriate application policies. The latter can relate to the information model you applied by reverting to Keyword Query Language (KQL), which allows the policies to search for matching information based on relevant queries.
In our example, such a query may address both the content type and an attribute, e.g. ‘contenttype: "Financial Information AND document category: Annual reports”’ – just the latter statement in the query would work as well in this case, as in our example there is only one instance of that document category.
As KQL can address all aspects of your information model, it is a very powerful way to automate retention in a direct manner. Hence, it is worthwhile investing into more elaborate information modeling, for this reason alone. It has other benefits as well: increasing the findability of information for your end users and applying business context allowing you to further automate information processing.
We hope this deep dive inspired you to enhance your information models in SharePoint Online and reach compliance faster and easier.
%20(300%20x%2060%20px)%20(3).png?width=635&height=127&name=ISO%20email%20signature%20(390%20x%2060%20px)%20(300%20x%2060%20px)%20(3).png)